GPT2 From Scratch
- Gianluca Turcatel
- Mar 28
- 3 min read
Updated: Apr 6

Introduction
In a previous post I coded the transformer from scratch and trained it to translate English to Italian. In this blog post I will code GPT2 and train to generate text from a short text. The code can be found HERE.
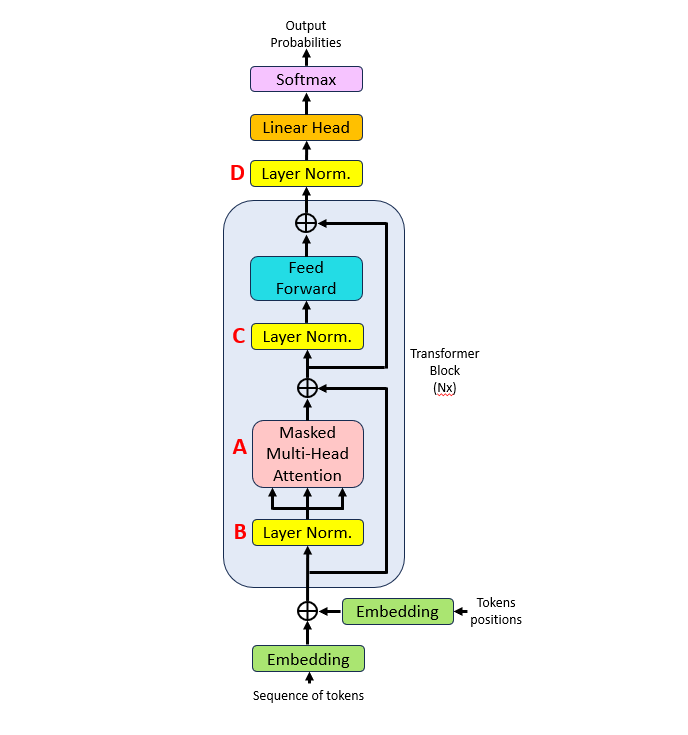
GPT2 is composed by a stack of N decoders. The GPT-2 decoder closely resembles the one described in the Attention Is All You Need decoder, but with a few key differences:
The cross-attention block is removed: in GPT-2, the cross-attention block—which measures similarity between encoder and decoder tokens—is absent because there are no encoders. Instead, only the masked multi-head attention layer is present (A).
The layer normalization precedes the masked multi-head attention layer (B).
In the feed-forward block, layer normalization occurs before the feed-forward network (FFN) (C).
An additional layer normalization is introduced before the final linear output layer (D).
All these changes are depicted in the image below:
The Data
I will use one of the Hugginface datasets "krvhrv/crawl-books" which contains ~660K chunks of several books covering various topics. The dataset is ~4.6GB. In the GPT2 paper trained was done with batch size of 512. With a context size of 1024 tokens, that equals to 524,288 tokens per batch.
During training, the entire dataset cannot fit into memory, so I divided it into shards of 20,971,520 tokens each (40 batches of 524,288 tokens each). The text was tokenized using the 'gpt2' encoder. After data preprocessing, 97 shards were obtained, totaling approximately 2 billion tokens. Here are some key aspects worth noting:
Chunks of text are concatenated together even when they belong to different books and are thus semantically unrelated.
Each chunk of text will be separated by the 'endoftext' token.
Shards will contain an extra token at the end to generate X and Y, since X and Y are shifted by one token. For example, suppose the text length is 4 tokens and the batch size is 2, making the shard size 8.
If X is |1, 2, 3, 4 | 5, 6, 7, 8 |, then Y will be |2, 3, 4, 5 | 6, 7, 8, 9 |. One shard will be saved as |1, 2, 3, 4, 5, 6, 7, 8, 9 |.
During training, each shard will be loaded by the ShardDataLoader class. However, we cannot pass 512 rows (equal to 524,288 tokens) to the model at once. Instead, we will pass minibatches of 16 rows to the model and accumulate gradients until reaching 524,288 tokens, at which point the model parameters will be updated.
Coding GPT2
1- Masked multi-head self-attention
The code for the masked multi-head self-attention is very similar to the one implemented in the transformer blog post. One major difference is that I used the scaled_dot_product_attention method from torch.nn.Functional to simplify the code. The argument 'is_causal' is set to True to enable causal masking, preventing tokens from accessing future tokens.
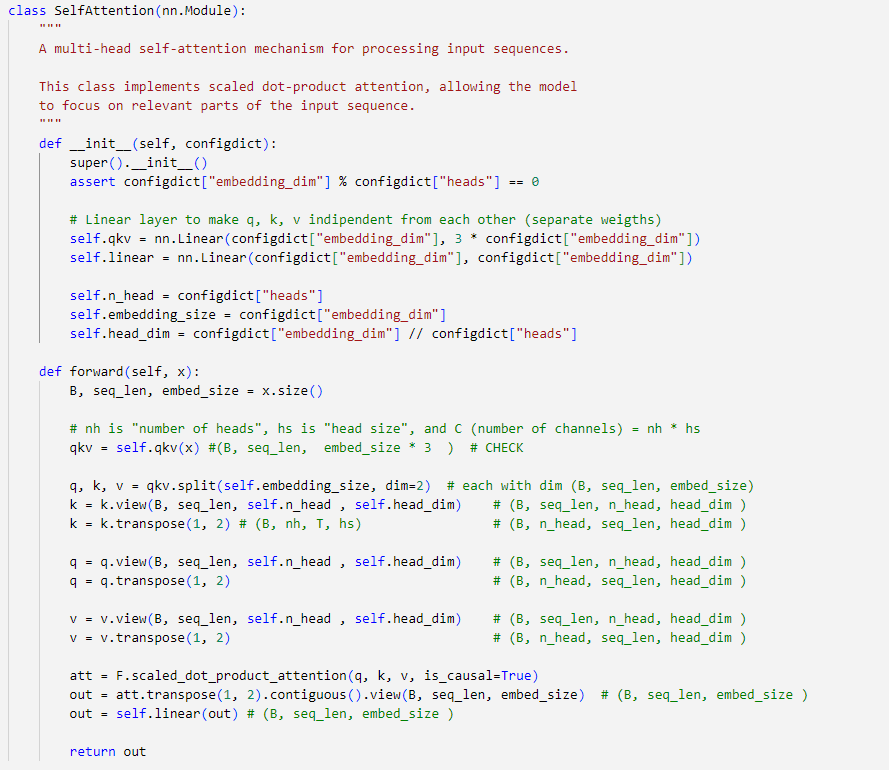
2- Transformer block.
A single transformer block contains masked multi-head self-attention and feed-forward layers.

3- GPT2 Model
The GPT2 class includes token and positional embeddings, multiple transformer blocks, one last layer normalization, and a final linear layer for token classification.

GPT2 training
CrossEntropyLoss was used to train the GPT2. Refer to the notebook HERE for details on the training steps. I applied few tricks to speed up the training:
I lowered the precision of the matrix multiplication from Float32 to TensorFloat32 (https://pytorch.org/docs/stable/generated/torch.set_float32_matmul_precision.html)
I lowered the precision of the torch layers to bfloat16 (https://pytorch.org/docs/stable/amp.html#autocasting)
The vocabulary size was increased from 50,257 to 50,304, which is a power of 2. Studies have shown that using power-of-2 values can help reduce training time.
I trained a small GPT-2 model (only 37M parameters) on 100 million tokens to confirm that it was indeed learning, as indicated by the gradual reduction in loss with each iteration:
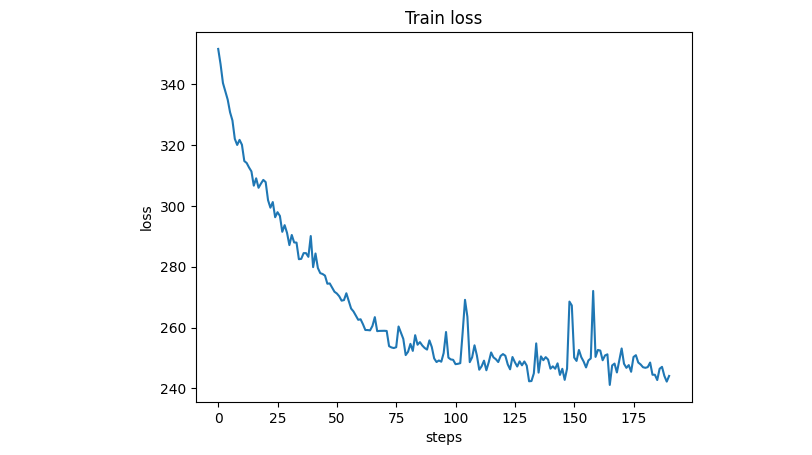
This very short training was insufficient to generate coherent text. For example, when the input "In the maintenance stage individuals" was passed to the trained model, the output was:
"In the maintenance stage individuals the is, with al the to with;; (– of: in; in the in et-..."
Conclusion
Building GPT-2 from scratch provides a deeper understanding of how transformer-based language models work, from tokenization and data preparation to model architecture and training optimizations. While the small-scale model demonstrates the learning process, training a fully functional GPT-2 requires significantly more data, compute, and longer training time. Nonetheless, the techniques and optimizations discussed here can be applied to larger models, making this a valuable starting point for anyone looking to explore generative language models further. Note that my implementation lacks some important features of the officially published GPT2 such as weight initialization and gradient clipping, among other optimizations.
Comments